Xin chào tuần mới các member Mì AI, chắc hẳn gần đây anh em có nghe nói về github FaceMaskDetection của mấy anh China về nhận diện mặt đeo khẩu trang khá đỉnh. Hôm nay chúng ta sẽ cùng triển khai lại Face Mask Detection bằng YOLO nhé.
Mình đã có 1 bài về nhận diện đeo khẩu trang/Face Mask Detection bằng OpenCV đơn giản hơn tại đây. Các bạn có thể tham khảo!
Mình xin nhắc lại là cái github trên mình thấy kha hay tuy nhiên với trình độ Mì của mình thì sau khi nghiên cứu thì thấy
- Mô hình khá phức tạp,
- Viết bằng Pytorch nên anh em khá oải khi nghiên cứu và triển khai.
- Không có source phần training mà chi có source để sử dụng pretrain để infer nên anh em cũng chả hiểu nó làm như nào ra được thế
Do đó, mình quyết định hì hụi chuyển sang YOLO để anh em làm cho dễ và cũng tập train cho vui vẻ. Ngoài ra bài này mình cũng sẽ đi sâu hơn về YOLO, về mạng, về output về các tham số….. Hi vọng sẽ mang lại nhiều thông tin bổ ích cho các bạn.
Phần 1 – Nói qua về model structure của FaceMaskDetection
Phần này mình nói khái quát theo hiểu biết của mình để các bạn tham khảo thôi nhé. Mình đã đọc qua và có mấy note như sau:
- Họ dùng backbone là SSD Lite với số tham số chỉ hơn 1M, với mục đích là để chạy nhanh trên trình duyệt.
- Đầu vao ảnh 260×260, với 8 lớp Convolution và đầu ra gồm 2 thông tin: class id và boundbox của khuôn mặt.
- Họ sử dụng 5 cụm output với anchor size khác nhau.
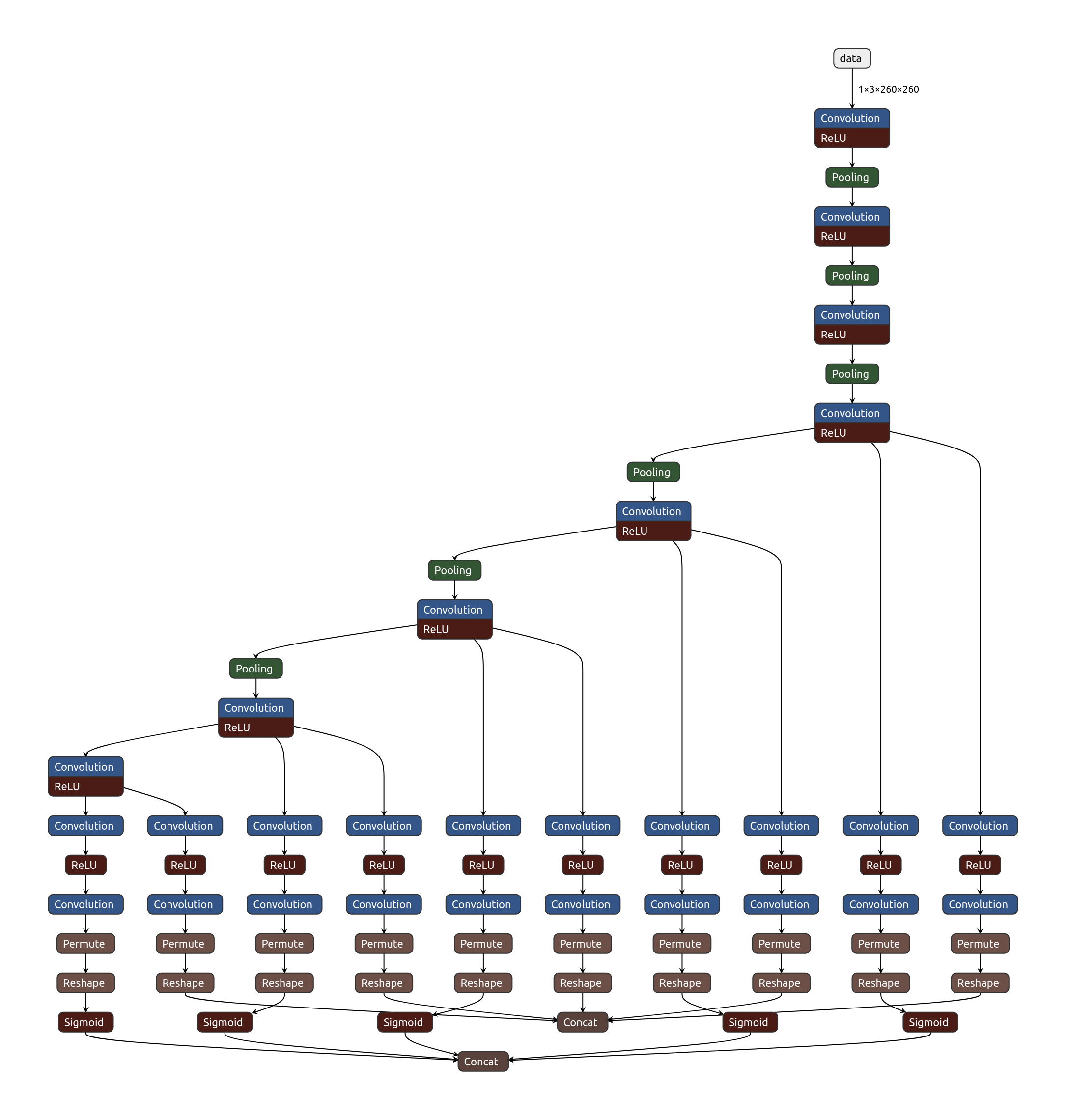
Rất may là dù họ không có source train, nhưng họ lại có public dataset và thế là anh em lại có trò chơi rồi. Và cùng YOLO thôi!
Phần 2 – Nói qua một chút về YOLO
Như chúng ta đã biết, YOLO là một mạng khá phổ biến hiện nay với cấu trúc như sau:
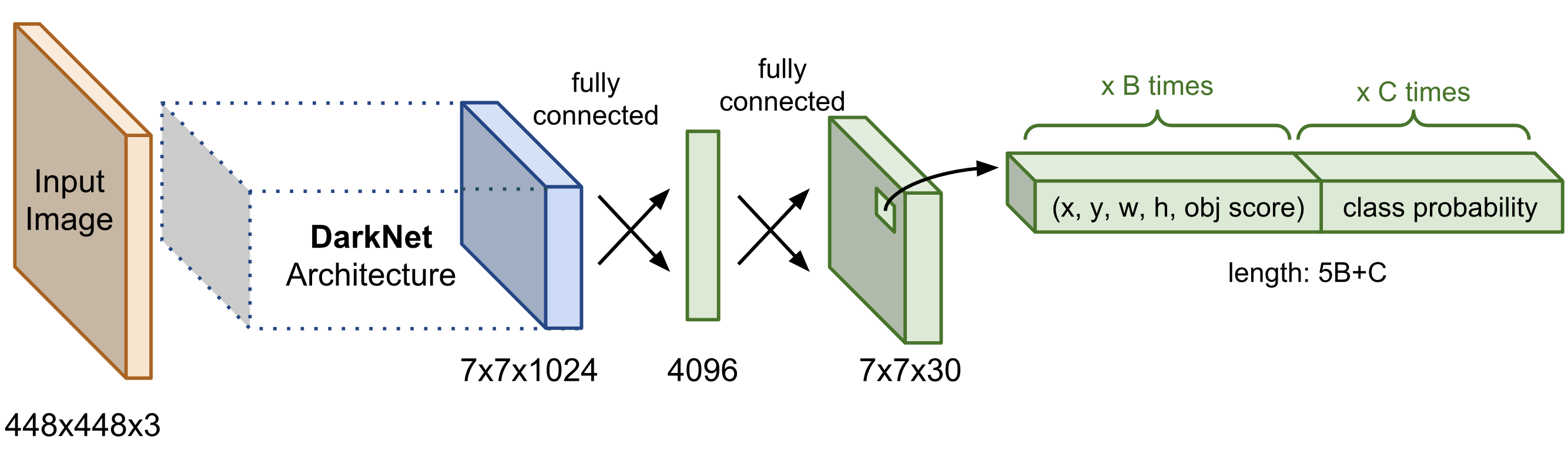
Phần đầu sẽ là các lớp trích xuất đặc trưng ảnh và di sau là các lớp Fully Connected làm công tác predict ra vị trí vật thể và các class của các vật thể đó.
Để các bạn dễ hiểu, mình xin phép được nói theo kiểu nôm na, dân dã làm sao anh em hiểu được và làm dược. Xin lỗi các nhà khoa học nếu có đi qua đây ah.
Đầu tiên là về số feature map
Sau khi ảnh đầu vào đưa vào phần trích xuất đặc trưng thì thông thường chúng ta sẽ thu được 1 feature map với kích thước nhỏ hơn rất nhiều ảnh ban đầu nhưng lại có “chiều sâu” lớn hơn rất nhiều và sẽ dùng features map (FM) đó để tiến hành predict tiếp theo. Với YOLO thì không chỉ có 1 FM mà sẽ là 3 FM khác nhau tùy vào size input đầu vào.
Ví dụ, input là 416×416 thì feature map có các kích thước là 13×13, 26×26 và 52×52 còn với input là 608×608 thì feature map sẽ là 19×19, 38×38 và 72×72. YOLO hỗ trợ cả 2 size input này.
Đái khái 1 ảnh nhét vào darknet sẽ ra 3 cái ảnh nhỏ hơn, gọi là feature maps. Còn làm gì với đống đó thì sang phần tiếp theo.
Định nghĩa anchor box
YOLO định nghĩa 3 anchor box sẵn, để từ đó dự doán vật thể cho từng cell trong FM. Hiểu đơn giản là cầm sẵn các khung ảnh có kích thước khác nhau, áp vào từng cell của FM để tạo ra 1 khung nhìn khác nhau và dự đoán vật thể.

Như hình trên chẳng hạn, là 2 cái khung ảnh, 1 cái dài, 1 cái ngang ốp vào để dự đoán người.
Khi train YOLO anh em để ý sẽ có các Region đó, giờ anh em đã hiểu nó là gì đúng ko?
Dự đoán trên các feature maps
Rồi với mỗi cái FM có được từ bước trên, ta sẽ xử lý tiếp để đoán ra các vật thể trong đó. Chúng ta tạm thời xét với 1 FM 13×13 thôi, các FM khác tương tự.
Chúng ta giả sử bài toán là train một model nhận diện chó và mèo trong ảnh (với chó có class id là 0 và mèo có class id là 1). Như vậy số class = 2 (chỉ có chó với mèo)
Vậy bây giờ làm gì với FM? Chúng ta sẽ dò từng cell trong FM theo hướng từ trên xuống dưới, từ trái sang phải và ốp các anchor box vào để dự đoán từng ô một có CHỨA TÂM CỦA vật thể không? tọa độ của vật thể là gì? Mà cái vật thể dó là cái giống gì (class = bao nhiêu ấy mà).

Từ đó ta thấy với 1 cell sẽ gồm các thông số output là:
- po: Là có vật thể hay ko? Hay là nền?
- tx, ty, tw, th: là vị trí vật thể. Trong đó tx và ty là tọa độ tâm, tw và th là rộng vào cao của box.
- p1….pc : Là probality dự đoán của các class. Ví dụ với bài toán chúng ta là 2 class thì chỉ có p1 và p2 thôi nhé 😉
Vậy 1 cell sẽ có số output là : (4 + 1 + 2) = 7
Tuy nhiên, YOLO ko áp 1 anchor box mà là 3 anchor box nên số output sẽ là 7×3 = 21.
Từ đó thì cả FM (13×13) sẽ là (13×13)x21 = 3,549.
Tính toán tương tự với các FM còn lại, chúng ta sẽ thấy số tham số output rất lớn và phép tính toán là cực lớn. Đó là vì sao train YOLO các bạn luôn thấy CPU, GPU lên cao 100%.
Chốt thông tin output tại mỗi cell của FM
Cuối cùng tại mỗi cell của FM, ta chọn anchor box nào có IOU lớn nhất. Vậy IOU là gì? Đó là Intersection Over Union. Nói nôm na là tỷ lệ chính xác giữa box dự đoán ra và box thật của vật thể. Giá trị càng cao càng tốt.

Khi train anh em để ý sẽ có tham số IOU này xuất hiện và tăng dần.
Bước cuối cùng là các cell gần nhau dễ bị dự đoán giống nhau, ví dụ như hình con chó bên dưới:

Con chó khá to nên các điểm gần nhau đều thuộc con chó nên đều được dự đoán ra hết. Tuy nhiên mục đích của chúng ta chỉ cần 1 khung hình chó mà thôi. Nên lúc nào YOLO áp dụng NMS – Non-max suppression đê remove bớt các khung hình và cho ra ảnh như bên phải.
Ớ thế khi train YOLO mọi người hay bảo khi nào Loss hội tụ thì dừng lại? Loss là gì?
Loss sẽ nôm na gồm 2 phần là Loss về dự đoán class và Loss về dự đoán bounding box cho vật thể. Khi train thì tham số Loss đứng ngay sau số vòng lặp, mọi người để ý tham số này để biết được model cần dừng lại hay chưa nhé.
Phần 3 – Tiến hành train model Face Mask Detection
Rồi dông dài đủ rồi. Bây giờ train model Face Mask Detection thôi, chắc anh em nóng lòng rồi!
Với dữ liệu public bởi tác giả, chúng ta không thể sử dụng ngay được vì các lý do:
- Một nửa dữ liệu được gán nhán với format PASCAL VOC , mình phán đoán phần dữ liệu này họ lấy tại WIDERFACE
- Một nửa còn lại thì là tại MAFA và gán nhãn không theo đúng chuẩn PASCAL VOC
Mình định lấy dữ liệu về convert sang YOLO Labels bằng script chuẩn trên mạng thì bị lỗi nên đành viết sửa lại script riêng cho nó. Script đại khắc phục bằng cách nếu như nhãn đầu vào không có tham số w,h thì sẽ đọc ảnh để tạo ra vậy.
import glob
import os
import pickle
import xml.etree.ElementTree as ET
from os import listdir, getcwd
from os.path import join
import cv2
dirs = ['train', 'val']
classes = ['face', 'face_mask']
def getImagesInDir(dir_path):
image_list = []
for filename in glob.glob(dir_path + '/*.jpg'):
image_list.append(filename)
return image_list
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(dir_path, output_path, image_path):
basename = os.path.basename(image_path)
basename_no_ext = os.path.splitext(basename)[0]
in_file = open(dir_path + '/' + basename_no_ext + '.xml')
out_file = open(output_path + basename_no_ext + '.txt', 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
try:
w = int(size.find('width').text)
h = int(size.find('height').text)
# Đây là đoạn check xem tham số có không? Nếu khôgn có thì read ảnh để lấy
if (w==0) or (h==0):
image = cv2.imread(image_path)
w, h = image.shape[1], image.shape[0]
del image
except:
image = cv2.imread(image_path)
w,h = image.shape[1],image.shape[0]
del image
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
cwd = getcwd()
for dir_path in dirs:
full_dir_path = cwd + '/' + dir_path
output_path = full_dir_path +'/yolo/'
if not os.path.exists(output_path):
os.makedirs(output_path)
image_paths = getImagesInDir(full_dir_path)
list_file = open(full_dir_path + '.txt', 'w')
for image_path in image_paths:
print(image_path)
list_file.write(image_path + '\n')
convert_annotation(full_dir_path, output_path, image_path)
list_file.close()
print("Finished processing: " + dir_path)Sau khi chạy 1 lúc thì mình đã có dữ liệu ảnh và nhãn chuẩn yolo và bây giờ thì đơn giản là thực hiện train theo các bài guide của mình trên blog thôi. Anh em nào chưa đọc thì tham khảo tại đây. Để anh em tiện train thì mình cũng chia sẻ luôn dữ liệu đã gán nhãn chuẩn YOLO chỉ việc train tại thư viện Mì AI ( link đây, các bạn nhớ xem video để biết cách tải nhé)
Sau khi mình train 6000 vòng thì nhận diện đã khá chuẩn, chấp các loại khẩu trang 😀

Anh em nào ngại có thể clone luôn mã nguồn Face Mask Detection/nhận diện đeo khẩu trang tại đây:
git clone https://github.com/thangnch/MIAI_Face_Mask_YOLOOk như vậy bài hôm nay mình đã guide các bạn thêm vài thông tin sâu hơn về YOLO cũng như cách tiền xử lý dữ liệu đầu vào khi dữ liệu không chuẩn. Chúng ta đã dưa về được label YOLO chuẩn và chỉ việc train thôi 😀
Chúc các bạn thành công!
Hãy join cùng cộng đồng Mì AI nhé!
Fanpage: http://facebook.com/miaiblog
Group trao đổi, chia sẻ: https://www.facebook.com/groups/miaigroup
Website: https://miai.vn/
Youtube: http://bit.ly/miaiyoutube
Cảm ơn anh về bài viết hữu ích ạ, em muốn hỏi chút là có thể kết hợp nhận diện Face Mask với Face Recognize để làm 1 hê thống chấm công mà không cần phải bỏ khẩu trang ra không ạ?
Thanks em
Về vụ này có 2 luồng ý kiến. Nên làm để tiện cho ng dùng và không nên làm vì nguy hiểm cho hệ thống. Vì che 1/2 mặt là bỏ bớt đi feature mà hệ thống của em vẫn phải nhận được. Vậy nếu có ai đó giống 1/2 mặt bên trên là hệ thống em tèo rồi.
Anh Thắng ơi, bài bị lỗi mất 1 ảnh phần “Chốt thông tin output tại mỗi cell của FM”
Thanks em. Để anh khắc phục nhé!