Chào tuần mới toàn thể anh em Mì AI, sau khi đã tìm hiểu về Transformer tại đây, hôm nay chúng ta sẽ tìm hiểu về BERT (Bidirectional Encoder Representations from Transformers), một SOTA trong làng NLP nhé.
Thực ra bài viết về BERT trên mạng cũng rất nhiều rồi, tuy nhiên thực sự mình đọc chẳng hiểu gì :(. Ở đây mình không có ý chê các tác giả đó viết chán nhé. Lý do chính bởi họ assume là người đọc đã hiểu rồi nên viết cực vắn tắt và dẫn đến là đọc xong cũng chả hiểu giờ muốn dùng BERT thì làm sao?
Ví dụ, khi tìm hiểu về BERT thì kiểu gì các bạn cũng gặp cái hình này:
Gớm không rõ các bạn như nào chứ mình thì chả hiểu, C rồi T1, Tn, Tsep là gì cả =)). Thành ra đọc xong để đấy chứ chưa xài gì.
Do đó mình quyết định viết 1 series về BERT theo cách Mì (các bác pro đi qua xin thứ lỗi cho và mong các bác sửa giúp nếu sai ah) gồm các phần: BERT là gì? Thực hành với BERT “tây” và BERT “ta” (PhoBERT).
Let’s go anh em ơi!
Phần 1 – BERT là gì?
Như đã nói ở trên, phần này chúng ta sẽ giải thích theo cách Mì ăn liền thôi nhé, cho nó dễ hiểu.
BERT là một model biểu diễn ngôn ngữ (Language Model- LM) được google giới thiệu vào năm 2018. Trước khi BERT ra đời thì các tác vụ như: phân loại cảm xúc văn bản (tốt hay xấu, tích cực hay tiêu cực), sinh văn bản, dịch máy,…. đều sử dụng kiến trúc RNN. Kiến trúc này có nhiều nhược điểm như train chậm, mất quan hệ giữa các từ xa nhau…., cái này mình đều đã nói trong video về transformer tại đây, các bạn xem lại phần đầu nhé.
Tại thời điểm công bố, BERT đã nhanh chóng trở thành bá đạo trong mảng NLP bởi những cải tiến chưa từng có ở những model trước đó như: tăng độ chính xác, GLUE score (General Language Understanding Evaluation score)… Bạn nào cần chi tiết thì đọc thêm paper gốc nhé.
Túm lại cái là BERT là một LM ngon nhất hiện nay (thời điểm viết bài), được train sẵn rồi, anh em cứ vác về mà thực hiện các bài toán riêng của mình.
Phần 2 – Làm thế quái nào mà BERT nó ngon hơn RNN?
Lý do chính là bởi nó có nhúng thêm ngữ cảnh (Context) vào trong các vector embedding các bạn ah. Ngữ cảnh là một thứ vô cùng quan trọng trong ngôn ngữ. Với các ngữ cảnh khác nhau thì các từ trong câu được hiểu theo ý nghĩa hoàn toàn khác nhau, các LM bỏ qua ngữ cảnh thì khó có thể đạt được chất lượng tốt.
Ngược về quá khứ ta sẽ thấy được sự phát triển của các phương pháp nhúng từ (word embbeding) qua thời gian.
Đầu tiên là món embedding không ngữ cảnh
Các bạn có để ý trước giờ mình dùng Word2Vec hay FastText không? Mỗi từ trong vocab sẽ có một vector để dại diện cho nó và trong bất cứ câu nào, đoạn văn nào thì từ đó vẫn chỉ được biểu diễn bởi vector đó.
Ví dụ ta có 2 câu:
- Hôm nay em đi chơi bóng đá
- Thằng kia nó chơi em anh ạ
Đó, 2 cái từ chơi kia rõ ràng nghĩa khác nhau (mình khỏi giải thích nghĩa nha kaka). Nhưng với việc nhúng từ không ngữ cảnh thì cả 2 từ này sẽ đều ánh xạ ra chung 1 vector word embedding và điều này đã làm giảm đi sự mềm mại và đa nghĩa của ngôn ngữ.
Tiếp theo là món embedding có ngữ cảnh một chiều
Người ta sử dụng các kiến trúc mạng RNN để có thể tạo ra mối quan hệ thứ tự giữa các từ trong câu, từ đó tạo ra vector nhúng từ có ngữ cảnh. Tuy nhiên việc này chỉ thực hiện được theo một chiều left-to-right hoặc right-to-left mà thôi. Một số mạng phức tạp hơn đã sử dụng BiLSTM để chạy dọc theo câu theo 2 hướng ngược nhau nhưng 2 hướng này lại độc lập, chả liên quan gì đến nhau nên có thể xem là một chiều mà thôi.
Ví dụ một case mà chiêu nhúng từ một chiều này fail nhé. Giả sử ta có bài toàn như sau:
- Câu văn gốc: “Hôm nay Nam đưa bạn gái đi chơi”
- Sau đó chúng ta che từ bạn gái đi và câu trên trở thành “Hôm nay Nam đưa [mask] đi chơi”.
- Yêu cầu bài toán là dự đoán ra từ đã được masking.
Rồi, với mặt thường của chúng ta thì ngay khi nhìn thấy câu này thì nghĩ ngay đến từ bạn gái =)). Thề luôn! Nhưng model thì không như vậy, do nó chỉ được training một chiều, nó sẽ dự đoán [mask] từ các word trước đó là “Hôm nay Nam đưa” và thế là kết quả [mask] có thể sẽ được dự là: “tiền”,”mắt”, “hàng”…. (tuỳ vào corpus của chúng ta).
Toang rồi! Trong khi đó nếu nó kết hợp thêm từ đi chơi ở sau thì có phải ngon không cơ chứ =)). Cơ mà đưa hàng đi chơi cũng có nghĩa ấy chứ nhỉ anh em =)) (fun tý các bạn nhá).
Và BERT đã đến và làm điều chúng ta cần
Ngay trong cái tên của BERT đã thấy ngay chữ Bidirectional (2 chiều) rồi. Tóm lại là một từ trong câu sẽ được biểu diễn một cách có liên quan đến cả từ trước lẫn từ sau, hay nói cách khác là liên quan đến tất cả các từ còn lại trong câu. Do đó khi ta che 1 từ trong câu đi, ví dụ như từ “bạn gái” bên trên thì lập tức model có thể predict ra khá chính xác vì dựa vào cả đoạn “Hôm nay Nam đưa” và “đi chơi” kaka.
Phần 3 – Kiến trúc của BERT ra sao?
Yeah, bạn nào đã xem bài trước của mình về transformer chắc còn nhớ cái mô hình mạng transformer này:

Rồi, bây giờ ông BERT nhà mình chặt transformer làm đôi, chỉ lấy phần Encoder bên trái và bỏ đi phần Decoder bên phải. Tóm lai chỉ còn cái đoạn mà nhét câu văn bản vào và đầu ra là các encoder output như hình:

Bạn nào chưa rõ về output Encoder là gì thì lại xem lại bài trước của mình về Transformer nha!
Phần 4 – Chặt một nửa vậy rồi train kiểu gì?
Chắc hẳn đây cũng là câu hỏi nhiều bạn thắc mắc. Mình cũng vậy! Đang học mạng Transformer, quen cách train bên đó giờ chặt một nửa thì train sao. Okie, mình sẽ cùng tìm hiểu cách train ngay sau đây.
BERT được train đồng thời 2 task gọi là Masked LM (để dự đoán từ thiếu trong câu) và Next Sentence Prediction (NSP – dự đoán câu tiếp theo câu hiện tại). Hai món này được train đồng thời và loss tổng sẽ là kết hợp loss của 2 task và model sẽ cố gắng minimize loss tổng này. Chi tiết 2 task này như sau:
Masked LM
Với task này, ta train sẽ thực hiện che đi tầm 15% số từ trong câu và đưa vào model. Và ta sẽ train để model predict ra các từ bị che đó dựa vào các từ còn lại (đúng như câu Nam đưa bạn gái đi chơi ở trên đó).
Cụ thể là:
- Thêm một lớp classification lên trên encoder output
- Đưa các vector trong encoder ouput về vector bằng với vocab size, sau đó softmax để chọn ra từ tương ứng tại mỗi vị trí trong câu.
- Loss sẽ được tính tại vị trí masked và bỏ qua các vị trí khác (để đánh giá xem model dự đoán từ mask đúng/sai ntn mà, các từ khác đâu có liên quan).

Next Sentence Prediction (NSP)
Với task này thì model sẽ được feed cho một cặp câu và nhiệm vụ của nó là output ra giá trị 1 nếu câu thứ hai đúng là câu đi sau câu thứ nhất và 0 nếu không phải. Trong quá trinh train, ta chọn 50% mẫu là Positive (output là 1) và 50% còn lại là Negative được ghép linh tinh (output là 0).
Cụ thể cách train như sau:
- Bước 1: Ghép 2 câu vào nhau và thêm 1 số token đặc biệt để phân tách các câu. Token [CLS] thêm vào đầu cầu Thứ nhất, token [SEP] thêm vào cuối mỗi câu. Ví dụ ghép 2 câu “Hôm nay em đi học” và “Học ở trường rất hay” thì sẽ thành [CLS] Hôm nay em đi học [SEP] Học ở trường rất vui [SEP]
- Bước 2. Mỗi token trong câu sẽ được cộng thêm một vector gọi là Sentence Embedding, thực ra là đánh dấu xem từ đó thuộc câu Thứ nhất hay câu thứ 2 thôi. Ví dụ nếu thuộc câu Thứ nhất thì cộng thêm 1 vector toàn số “0” có kích thước bằng Word Embedding, và nếu thuộc câu thứ 2 thì cộng thêm một vector toàn số “1”.
- Bước 3. Sau đó các từ trong câu đã ghép sẽ được thêm vector Positional Encoding vào để đánh dấu vị trí từng từ trong câu đã ghép (bạn nào chưa biết thì xem lại bài về Transformer nhé).
- Bước 4. Đưa chuỗi sau bước 3 vào mạng.
- Bước 5. Lấy encoder output tại vị trí token [CLS] được transform sang một vector có 2 phần tử [c1 c2].
- Bước 6. Tính softmax trên vector đó và output ra probality của 2 class: Đi sau và Không đi sau. Để thể hiện câu thứ hai là đi sau câu thứ nhất hay không, ta lấy argmax là okie 😉
Các bước tạo Input:
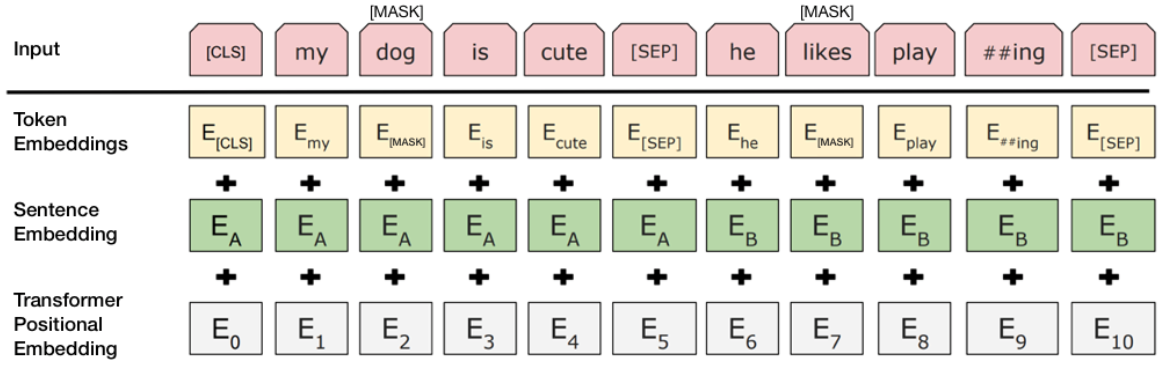
Và đây là cách lấy output đầu ra:

Rồi, thế rồi người ta đưa dữ liệu vào, vô số dữ liệu và train trông một khoảng thời gian dài với bao nhiêu công sức, tiền điện, hao mòn máy móc thì chúng ta đã có một Pretrain Language Model ngon nghẻ.
Mô hình BERT bằng tiếng Anh ban đầu đi kèm với hai dạng tổng quát được đào tạo trước:[1]: (1) mô hình the BERTBASE, kiến trúc mạng NN chứa 12-lớp, 110M tham số, và (2) mô hình BERTLARGE model, kiến trúc chứa 24-lớp, 340M tham số. Cả hai đều được huấn luyện từ BooksCorpus[4] với 800M từ, và một phiên bản của Wikipedia tiếng Anh với 2,500M từ.
Một lần nữa cảm ơn các tiền bối! Và ơn giời là chúng ta có thể Transfer Learning, sử dụng BERT cho các task khác một cách rất đơn giản. Trong bài sau mình sẽ cùng các bạn thử một vài task nhé.
Còn bây giờ xin chào tạm biệt!
Chúc các bạn thành công!
#MìAI
Fanpage: http://facebook.com/miaiblog
Group trao đổi, chia sẻ: https://www.facebook.com/groups/miaigroup
Website: https://miai.vn/
Youtube: http://bit.ly/miaiyoutube
Tài liệu tham khảo: https://towardsdatascience.com/bert-explained-state-of-the-art-language-model-for-nlp-f8b21a9b6270
-
-
-
-
-
-
-
-
-
-
Show CommentsHay quá anh ơi, em cũng đang cần làm về phần này mà đi học mấy cái khác không hiểu. May có anh viết bài. <3
Hihi, rất vui khi giúp được em.
Nếu cần thêm gì, em cứ post lên Group trao đổi, chia sẻ: https://www.facebook.com/groups/miaigroup nhé! Cho tiện trao đổi!
hi vọng a ra hết series sớm ạ ,cảm ơn a
Cảm ơn bạn. Cuối năm việc ở Bank bận quá kaka 😀
[…] ở cuối câu. Lý do vì sao lại thế thì các bạn xem lại bài trước của mình tại đây […]
[…] cùng các bạn tìm hiểu về BERT. Bạn nào chưa xem thì có thể xem lại tại đây [BERT Series] Chương 1. BERT là cái chi chi? và [BERT Series] Chương 2. Nghịch một chút với Hugging […]
Hay quá anh ơi, Em đang đọc về bert để làm bài thì có bài này giải thích thêm
Em post lên Group trao đổi, chia sẻ: https://facebook.com/groups/miaigroup cho tiện trao đổi nhé!
Tính đến tháng 10/2024 thì BERT còn là LM ngon nhất không anh?
Hehe. Nó còn tuỳ áp dụng vào task nào em ạ. Em post lên Group trao đổi, chia sẻ: https://facebook.com/groups/miaigroup thảo luận cho vui nha!