Chào anh em. Hôm nay chúng ta sẽ cùng nhau đi tìm hiểu về DataLoader, món đặc trị hiếu bộ nhớ, tràn RAM khi train model nhé. Let’s go anh em!
Mấy ngày nay trên Group nhiều anh em hỏi về vấn đề train model với nhiều dữ liệu. Một số câu hỏi phổ biến như:
- Em có khoảng 100.000 ảnh thì train có đủ bộ nhớ không, có bị lỗi không? Có train được không?
- Em load dữ liệu vào train thì toàn bị báo lỗi OOM – Out of memory và thoát chương trình luôn. Em phải làm sao?
- Em đã có batch size nhỏ rồi mà vẫn bị báo lỗi thiếu bộ nhớ là sao ạ?

Hôm nay chúng ta sẽ cùng nhau xử lý các vấn đề đó một cách đơn giản và dễ hiểu theo đúng phong cách Mì ăn liền nhé.
Thực ra mình cũng đã có một bài khác về vấn đề đặc trị tràn bộ nhớ rồi, đó là bài về Flow from directory (link: https://www.miai.vn/2020/10/27/flow-from-directory-thuoc-dac-tri-het-ram-tran-bo-nho-khi-train-model/). Tuy nhiên bài đó ta sử dụng thư viện của Keras và phù hợp với bài toán classify hơn. Lần này chúng ta sẽ cùng tìm hiểu một món tổng quát hơn, dùng được nhiều trường hợp hơn.
Bắt đầu thôi!
Flow dữ liệu thông thường khi train model
Để có thể hiểu được việc thiếu bộ nhớ thường xảy ra ở đâu và tìm ra cách khắc phục thì chúng ta cần hiểu rõ flow dữ liệu trong một bài toán train model thông thường sẽ như nào. Mình vẽ hình để các bạn tiện hình dung nhé (chú ý là mình chỉ focus vào phần dữ liệu).
Bài toán giả định hôm này là train model phân loại các loại chó qua ảnh nhé.
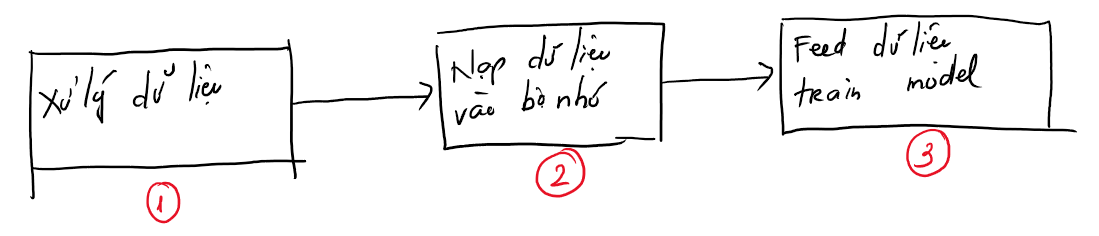
Theo như hình trên ta có thể thấy, OOM có thể xảy ra nhiều nhất ở 2 giai đoạn đó là Nạp dữ liệu vào bộ nhớ và Feed dữ liệu để train model. Cụ thể hơn:
- Khi chúng ta nạp toàn bộ dữ liệu gồm ảnh và nhãn (loại chó) vào bộ nhớ thì nếu như số ảnh nhiểu, kích thước ảnh lớn thì sẽ ngay lập tức đi đời bộ nhớ RAM luôn. Trong bài này mình chơi ảnh 600x600x3 và số ảnh tầm 1,200 ảnh thì đi toi luôn 10GB memory. Với máy 4GB, 8GB RAM thì chắc chết sớm, máy mình 32GB RAM nên vẫn trụ được để mà thoát ứng dụng trước khi quá muộn =))
- Giả sử chúng ta đủ bộ nhớ để nạp dữ liệu đi chẳng hạn thì khi chúng ta đưa ảnh vào train model cũng có khả năng OOM. Nếu train bằng CPU thì sẽ tốn thêm bộ nhớ RAM, còn train bằng GPU thì sẽ phụ thuộc vào VRAM của GPU. Chúng ta có thể khắc phục bằng cách thay đổi batch_size cho phù hợp.
Như vậy bài này chúng ta sẽ tập trung vào phần nạp dữ liệu và train model bằng dữ liệu vừa nạp sao cho không bị tràn bộ nhớ.
Code train model theo cách nạp toàn bộ dữ liệu vào bộ nhớ
Thử phân tích một đoạn code nạp dữ liệu theo cách thông thường trên mạng, đó là nạp toàn bộ vào bộ nhớ như sau (code full mình để trên github ở cuối bài) :
w, h = 600, 600
# Load data
data_folder = 'dog_CLASS/'
data = []
label = []
for folder in os.listdir(data_folder):
for file in os.listdir(os.path.join(data_folder, folder)):
file_path = os.path.join(data_folder, folder, file)
# Read
image = cv2.imread(file_path)
# Resize
image = cv2.resize(image, dsize=(w, h))
# Add to data
data.append(image)
label.append(folder)Chúng ta thấy rằng đoạn code trên duyệt qua tất cả các file trong tất cả các folder, sau đó đọc ảnh, resize về kích thước 600,600 và thêm vào 2 “mảng” (tạm gọi). Một mảng chứa ảnh và 1 mảng chứa nhãn (tên folder).
Sau đó chúng ta train model bằng lệnh fit thông thường:
# Fit to model
X_train, X_test, y_train, y_test = train_test_split(data, label, test_size=0.2)
hist = model.fit(X_train, y_train, epochs=2, validation_data=(X_test, y_test), verbose=1, batch_size=8)
Hai đoạn code trên thì đã quá quen thuộc với các bạn đọc các bài của Mì AI. Tuy nhiên, với dữ liệu nhiều thì ngay lập tức toan bộ nhớ RAM ngay ở bước nạp ảnh bên trên.
Vấn đề của chúng ta là trong khi model train theo batch_size (từng tý một) thì chúng ta lại nạp toàn bộ dữ liệu vào bộ nhớ trước dẫn đến tràn bộ nhớ. Vậy giải pháp là sẽ load tùng tý một theo batch_size vào bộ nhớ, khi load xong thì đưa cho model train rồi lại đi load tiếp 🙂
Code train sử dụng phương pháp load từng tý một với DataSet, DataLoader
Nếu như bài trước chúng ta sử dụng Flow from Directory của Keras và chúng ta chỉ khai báo biến và dùng là xong thì lần này chúng ta sẽ phỉa build from scratch.
DataLoader là một món dùng để load dữ liệu theo batch_size và trả cho model để model “nuốt” và train. Một DataLoader cần các đầu vào và đầu ra như sau:
- Đầu vào: Dataset, Batch_size
- Đầu ra: Từng lô dữ liệu gọi là Batch (batch dịch ra là lô, bó) và có kích thước = batch_size điểm dữ liệu được lấy ra từ dataset (load vừa đủ để đưa cho model train thôi).
Vậy là ta lại cần tìm hiểu tiếp DataSet là gì? DataSet dịch thô là bộ dữ liệu. Thực tế nó là một class để mô tả rằng mình có data như nào, nhãn ra sao, kích thước ảnh bao nhiêu và nhiều tham số khác tùy vào mục đích sử dụng của bạn. Nó cũng gồm một hàm để trả về một item trong DataSet, chúng ta sẽ có thể đưa vào các hàm tiền xử lý ảnh ở trong hàm get_item này.
Để hiểu rõ hơn ta lại xem hình sau:
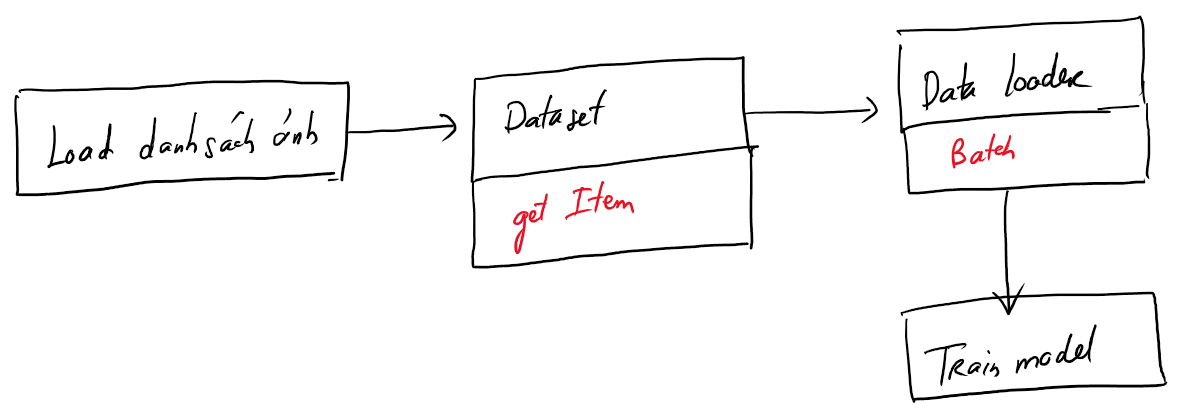
Giờ ta cùng phân tích flow trên để hiểu vì sao OOM sẽ được hạn chế:
Thứ nhất, tại bước đầu tiên ta không load toàn bộ ảnh vào bộ nhớ mà chỉ load danh sách các ảnh mà thôi. Mà danh sách ảnh thì toàn là các đường dẫn, đâu có tốn bao nhiêu bộ nhớ. Đoạn code mới sẽ là:
data = []
label = []
for folder in os.listdir(data_folder):
for file in os.listdir(os.path.join(data_folder, folder)):
file_path = os.path.join(data_folder, folder, file)
data.append(file_path)
label.append(folder)Vậy đến đây các bạn sẽ thắc mắc là thế load ảnh khi nào, chúng ta sẽ viết trong DataSet nhé:
class Dataset:
def __init__(self, data, label, w, h):
# the paths of images
self.data = np.array(data)
# the paths of segmentation images
# binary encode
label_encoder = LabelEncoder()
integer_encoded = label_encoder.fit_transform(label)
onehot_encoder = OneHotEncoder(sparse=False)
integer_encoded = integer_encoded.reshape(len(integer_encoded), 1)
onehot_encoded = onehot_encoder.fit_transform(integer_encoded)
self.label = onehot_encoded
self.w = w
self.h = h
def __len__(self):
return len(self.data)
def __getitem__(self, i):
print("Build model")
# read data
image = cv2.imread(self.data[i])
image = cv2.resize(image, (self.w, self.h))
label = self.label[i]
return image, labelBạn cứ hiểu như này cho dễ: trước đây là ta yêu cầu toàn bộ học sinh dù chưa làm gì cũng bật máy tính ngồi chờ sẵn nên sập bố nó hệ thống điện của nhà trường. Còn bây giờ ta sẽ ghi lại tên của toàn bộ học sinh và bảo các em ngồi chờ sẵn, khi nào gọi tên thì mới bật máy tính, dùng xong thì lại tắt đi :). Thế là ngon!
Một số điểm anh em lưu ý:
- Hàm __getitem__ chỉ được chạy khi ảnh tương ứng cần đưa vào DataLoader để feed cho model train.
- Anh em có thể đưa nhiều bước tiền xử lý ảnh, xử lý nhãn vào trong __getitem__ trước khi trả về tùy theo bài toán.
Thứ hai, DataLoader sẽ load theo lô có kích thước nhỏ vừa đủ cho model train thông qua Dataset:
class Dataloader(tf.keras.utils.Sequence):
def __init__(self, dataset, batch_size, size):
self.dataset = dataset
self.batch_size = batch_size
self.size = size
def __getitem__(self, i):
# collect batch data
start = i * self.batch_size
stop = (i + 1) * self.batch_size
data = []
for j in range(start, stop):
data.append(self.dataset[j])
batch = [np.stack(samples, axis=0) for samples in zip(*data)]
return tuple(batch)
def __len__(self):
return self.size // self.batch_sizeAnh em cũng để ý cái hàm __getitem__ nhé. Lần này là get 1 lô (batch) để đưa cho model nghĩa là nó lấy ra 1 số phần tử trong dataset và trả về. Mỗi khi nó gọi self.dataset[j] thì lúc đó phần tử/ảnh đó mới được load vào bộ nhớ bằng hàm __getitem__ trong Dataset (và dùng xong tất nhiên là giải phóng) chứ không load sạch như trước nữa.
Đây là cách chia dữ liệu, tạo Dataset và DataLoader
# Fit to model
X_train, X_test, y_train, y_test = train_test_split(data, label, test_size=0.2)
# Build dataaset
train_dataset = Dataset(X_train, y_train, w, h)
test_dataset = Dataset(X_test, y_test, w, h)
# Loader
train_loader = Dataloader(train_dataset, 8, len(train_dataset))
test_loader = Dataloader(test_dataset, 8, len(test_dataset))Vậy thì hàm train model cũng sẽ sửa đi một chút:
model = get_model(input_size=(w, h, 3))
hist = model.fit_generator(train_loader, validation_data=test_loader, epochs=2, verbose=1)Okie, vậy là xong. Mình đã chỉ các bạn cách sử dụng DataLoader, món đặc trị hiếu bộ nhớ, tràn RAM khi train model nhé. Chúc các bạn thành công!
Mình xin chia sẻ github link tại đây: https://github.com/thangnch/MiAI_DataLoader
Còn về dữ liệu thì các bạn lấy dữ liệu 10 loài chó trong Thư viện Mì AI nhé: https://miai.vn/thu-vien-mi-ai/
#MìAI
Fanpage: http://facebook.com/miaiblog
Group trao đổi, chia sẻ: https://www.facebook.com/groups/miaigroup
Website: https://miai.vn/
Youtube: http://bit.ly/miaiyoutube