Hi all anh em, hôm nay chúng ta sẽ cùng nhau tìm hiểu về YOLO v5 và làm luôn bài toán chẩn đoán X-Quang cùng bộ dữ liệu của VinBigData nhé!
Phần 1 này chúng ta tìm hiểu lý thuyết, tải dữ liệu, xử lý và chia dữ liệu để chuẩn bị cho Phần 2 sẽ train và đưa model lên web.
Trước tiên mình xin phép được sử dụng dữ liệu của VinBigDatađể làm bài này. Bài này hoàn toàn phi lợi nhuận, vì mục đích giáo dục.
YOLOv5 được yêu cầu rất nhiều bởi members trên Mì AI và đó là lý do mình ra bài này. Khác với các bài trước về YOLO, bài này mình sẽ guide các bạn từ A-Z để xây dựng một sản phẩm hoàn thiện.
Phần 1 – Lịch sử dòng họ YOLO
YOLO phiên bản 1 ra mắt lần đầu năm 2016 và sau đó đã qua nhiều phiên bản YOLO9000 (2017), YOLOv3 (2018) và YOLOv4 (2020) với nhiều cải tiến vượt trội về tốc độ và độ chính xác.

Trên Mì AI cũng đã có một loạt bài về YOLO v3, v4 rồi. Các bạn có thể truy cập vào link này để đọc nhé: https://www.miai.vn/?s=yolo
Tuy nhiên, có một cái lạ là ngay sau khi YOLOv4 ra được vài ngày thì tòi ra ông YOLOv5. Lúc đó có hai luồng tư tưởng:
- Một bên ủng hộ YOLOv5
- Một bên bảo không được đặc YOLOv5 vì chưa có paper chứng thực gì cả.
Thôi thì với anh em ứng dụng thì cứ ngon là anh em quất, quan trọng gì tên nó là gì đâu nhỉ :D. Mạng này thì ngon vãi luôn nè:

Do đó, anh em nếu có quất YOLO thì quất luôn YOLO v5 cho nó hoành nhé!
Phần 2 – Tìm hiểu về YOLO v5 “hơi sâu” một tý
Gọi là tìm hiểu hơi sâu thôi nhé, vì chúng ta sẽ tìm hiểu để áp dụng được thôi. Bạn nào cần viết paper, cần báo cáo đồ án thì chịu khó đọc thêm chi tiết về kiến trúc, về mã nguồn…. nhé!
Nói một cách chung chung thì YOLOv5 sử dụng Pytorch – một framework deep learning khác nhé anh em, ah em nào chưa biết thì có thể đọc tại link này.
Khác với các bản YOLO trước, YOLOv5 cung cấp luôn 4 phiển bản với kiến trúc mạng khác nhau:
- yolov5-s which is a small version
- yolov5-m which is a medium version
- yolov5-l which is a large version
- yolov5-x which is an extra-large version
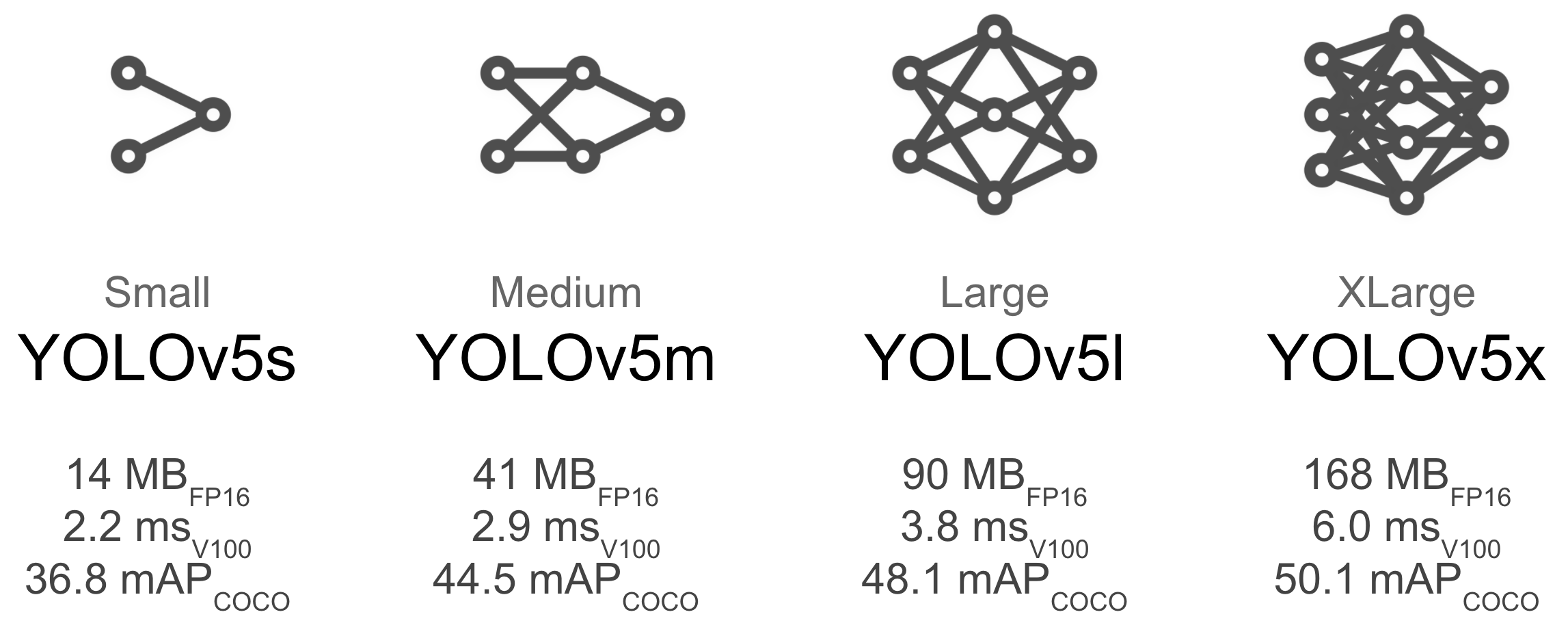
Tất nhiên, mạng to thì độ chính xác cao hơn nhưng tốc độ train và inference sẽ thấp hơn rồi. Tùy vào nhu cầu của bạn để bạn lựa chọn tốc độ hay độ chính xác nhé. Anh em có thể tham khảo tốc độ và độ chính xác qua hình vẽ bên trên.
Trong bài này mình sẽ sử dụng model Yolo5x – mạng to nhất cho nó máu nhé 😀
Phần 3 – Chuẩn bị dữ liệu train YOLO v5
Bài này như đã nói mình sẽ sử dụng bộ dữ liệu của cuộc thi VinBigData Chest X-ray Abnormalities Detection ( https://www.kaggle.com/c/vinbigdata-chest-xray-abnormalities-detection/data ).
Tải dữ liệu
Dữ liệu cuộc thi này khá lớn (tận 190GB) do ghi ở dạng ảnh DICOM format (link tìm hiểu thêm tại đây), một dạng ảnh sử dụng lưu trữ trong Y học. Chúng ta có thể tự dùng thư viện PyDicom để đọc và sau đó loại bỏ các thông tin không cần thiết, chỉ lưu lại phần ảnh với mục đích giảm dung lượng dataset.
Chú ý: Bạn đọc kỹ phần mô tả của bộ dataset này để sau còn hiểu Class 14, 13, 1… là cái gì nhé. Cụ thể:
0 - Aortic enlargement
1 - Atelectasis
2 - Calcification
3 - Cardiomegaly
4 - Consolidation
5 - ILD
6 - Infiltration
7 - Lung Opacity
8 - Nodule/Mass
9 - Other lesion
10 - Pleural effusion
11 - Pleural thickening
12 - Pneumothorax
13 - Pulmonary fibrosis
Tuy nhiên, có một cách nhanh hơn là ta có thể tải sẵn bộ dataset đã convert sang PNG tại Thư viện Mì AI: https://www.miai.vn/thu-vien-mi-ai/.
Sau khi tải về chúng ta sẽ có một file tên là VINAI_Chest_Xray.zip (4GB – File này do một bạn tên Nguyễn Thành Trung convert sẵn nhé, mình chỉ tải về thôi, hiện chưa tìm lại được link tải để đưa vào đây). Giải nén file này ra chúng ta sẽ có :
- Một file train_downsampled.csv – chứa thông tin về ảnh, nhãn của các vùng chẩn đoán trong ảnh.
- Một folder train: Chứa các ảnh để train model
- Một folder test: Chứa các ảnh để test model.
Rồi bây giờ ta sang phần tiếp theo là tiền xử lý dữ liệu!
Tiền xử lý dữ liệu, convert về YOLO5 format
Quan sát nhanh tập dữ liệu ta có các thông tin sau đây:
- Các file ảnh trong tập train không có kích thước cố định nên không thể hardcode width height khi convert.
- Trong file csv cũng không có width, height của ảnh nên ta sẽ phải đọc ảnh để biết kích thước trước khi convert.
- Một file ảnh có nhiều kết quả chẩn đoán của nhiều bác sĩ khác nhau. Chỗ này tối ưu tốt là có giải nhưng mình gà và bài này ở mức demo nên mình cứ để nguyên và train nhé.
- Do là bài toán detection nên ta sẽ bỏ qua các class 14 (không có bệnh) trong file csv

Vậy là cách làm như sau:
- Đọc file CSV, lấy tên file và tọa độ box, nhãn của các chẩn đoán trong file đó.
- Đọc file ảnh để biết kích thước ảnh .
- Convert sang YOLO format và ghi vào folder train (nằm cạnh file ảnh) với tên giống file ảnh và phần mở rộng là txt.
Anh em chú ý một điều nữa là :
- Trong file csv ghi tọa độ góc trên và dưới của box chẩn đoán theo pixel.
- Còn YOLO format thì lại là tọa độ tâm của box và kích thước rộng, dài và tất cả được chia cho width, height của ảnh để chuẩn hóa về khoảng [0,1]
Và đây là code convert của mình. (Chú ý: Dữ liệu này search trên mạng có thể có sẵn và không cần convert, nhưng mình sẽ viết để các bạn hiểu cách làm, và có thể cách này của mình chưa phải là cách tối ưu nha :D)
import pandas as pd
import cv2
import os
import pickle
# Đọc file CSV
csv_file = "G:\\VINAI_Chest_Xray\\train_downsampled.csv"
df = pd.read_csv(csv_file)
print(df.head())
# Lặp qua các file trong thư mục train
raw_folder = "G:\\VINAI_Chest_Xray\\train\\train"
idx = 0
file_list = []
for file in os.listdir(raw_folder):
if file[0] != ".": # Ignore temp file
print("Xử lý file {}- {}".format(idx, file))
idx += 1
# Tìm xem trong CSV có nhãn nào cho file và chỉ lọc các bản ghi có class_id khác 14
df_find = df[(df.image_id == file[:-4]) & (df.class_id != 14)]
# Nếu tìm thấy bản ghi phù hợp
if len(df_find) > 0:
# Đọc file ảnh để lấy kích thước
raw_image = cv2.imread(os.path.join(raw_folder, file), 0)
image_width, image_height = raw_image.shape[1], raw_image.shape[0]
labels = []
# Lặp qua từng bản ghi trong df_find để tính toán
for index, row in df_find.iterrows():
# Tính tọa độ tâm và kích thước theo pixels
box_width = row[6] - row[4]
box_height = row[7] - row[5]
box_center_x = (row[6] + row[4]) / 2
box_center_y = (row[7] + row[5]) / 2
# Thực hiện chuẩn hóa
box_width_normalized = box_width / image_width
box_height_normalized = box_height / image_height
box_center_x_normalized = box_center_x / image_width
box_center_y_normalized = box_center_y / image_height
# Ghi thông tin nhãn vào list
labels.append([row[2], box_center_x_normalized, box_center_y_normalized, box_width_normalized, box_height_normalized])
# Lặp qua list và ghi vào file txt
txt_file = file[:-4] + ".txt"
with open(os.path.join(raw_folder, txt_file),'w') as f:
for label in labels:
f.write('{} {} {} {} {}\n'.format(label[0],label[1],label[2],label[3],label[4]))
print("Ghi xong nhãn ", txt_file)
file_list.append(file)
print("Số file có nhãn = ", len(file_list))
# Ghi file_list vào file pickle
with open('file_list.pkl','wb') as f:
pickle.dump(file_list,f)Code language: PHP (php)Okie, sau khi chạy xong đoạn lệnh này thì anh em hãy mở thử thư mục train xem, sẽ thấy ngay một loạn file txt đã được tạo ra ghi nhãn! Một số file không có file txt đi kèm vì file ảnh đó không có chẩn đoán bệnh.


Ngoài ra, ta cũng tạo ra một file file_list.pkl chứa các ảnh có nhãn.
Okie rồi đó, vậy là công tác tạo data đã xong. Đến bước tổ chức lại dữ liệu thô này để train model.
Chia dữ liệu thành train,val theo đúng cấu trúc Yolo v5
Chú ý: Trong đoạn code trên hoàn toàn có thể thực hiện việc chia train,val ngay khi tạo ra txt nhưng mình muốn tách thành hai process để các bạn mới tiếp cận đỡ nhầm lẫn. Sau khi quen rồi các bạn có thể merge 2 code vào cho tiện.
Cấu trúc mà YOLO v5 yêu cầu gồm:
- Một thư mục images chứa ảnh: trong đó có 2 thư mục train và val để chứa ảnh train và ảnh validation.
- Một thư mục labels chứa nhãn (các file txt đó) và cũng có 2 thư mục tương tự như images.

Và đây là code để chia 20% ảnh cho validation và 80% cho train:
import shutil
import os
import random
import pickle
raw_folder = "G:\\VINAI_Chest_Xray\\train\\train"
with open('file_list.pkl','rb') as f:
file_list = pickle.load(f)
total_files = len(file_list) # Tổng số file có nhãn trong thư mục train
print("Tổng số file = ", total_files)
# Anh em tạo sẵn thư mục này nếu chưa có nhé :D Mình khỏi viết hàm check ở đây hehe
train_folder = "G:\\VINAI_Chest_Xray\\yolo_data\\images\\train"
val_folder = "G:\\VINAI_Chest_Xray\\yolo_data\\images\\val"
train_labels_folder = "G:\\VINAI_Chest_Xray\\yolo_data\\labels\\train"
val_labels_folder = "G:\\VINAI_Chest_Xray\\yolo_data\\labels\\val"
# Tạo ra index cho train, val
total_files_validation = int(0.2 * total_files) # 20% cho validation
validaiton_files = random.choices(file_list, k=total_files_validation)
print("Số bản ghi validation = " , len(validaiton_files))
# Copy images và labels to validation folder
for file in validaiton_files:
print("Validation file ", file)
# Copy images
shutil.copy(os.path.join(raw_folder, file), os.path.join(val_folder, file))
# Copy labels
shutil.copy(os.path.join(raw_folder, file[:-3] + 'txt'), os.path.join(val_labels_folder, file[:-3] + 'txt'))
# Copy images và labels to train folder
for file in total_files:
if not (file in validaiton_files):
print("Train file ", file)
# Copy images
shutil.copy(os.path.join(raw_folder, file), os.path.join(train_folder, file))
# Copy labels
shutil.copy(os.path.join(raw_folder, file[:-3] + 'txt'), os.path.join(train_labels_folder, file[:-3] + 'txt'))
Code language: PHP (php)Okie, sau khi chạy xong bạn sẽ có các thư mục chứa đầy ảnh và nhãn sẵn sàng cho train model.
Tuy nhiên, bài này cũng dài rồi nên mình sẽ tách phần train và triển khai sang bài khác nhé. Mình sẽ viết ngay thôi, để các bạn đỡ phải đợi! Toàn bộ source code sẽ được chia sẻ trong Phần 2 nha!
Phần 2 đã có tại đây: https://www.miai.vn/2021/03/03/thu-lam-bac-si-chuan-doan-x-quang-cung-yolo-v5-phan-2-2/
Chúc các bạn thành công!
#MìAI
Fanpage: http://facebook.com/miaiblog
Group trao đổi, chia sẻ: https://www.facebook.com/groups/miaigroup
Website: https://miai.vn
Youtube: http://bit.ly/miaiyoutube
https://www.kaggle.com/raddar/vinbigdata-competition-jpg-data-3x-downsampled?fbclid=IwAR0kekKyXuwYGNDkMepnhj5eTAeU3W3wIeaFoSDX_Kx1nejCfePyUFb6Q2A
Em thấy có bộ convert và scale xuống 3 lần. Nên em chia sẻ cho mọi người để tham khảo và góp ý ạ
Anh ơi,
Em cảm ơn các bài viết hay và bổ ích của anh ạ. Nhất là bài này vì em đang gặp một số lỗi khi train yolo với data này.
Nhưng mà em có góp ý nho nhỏ ạ, bởi vì Vingroup có nhiều P&L về AI nên có thể mọi người sẽ hơi nhầm lẫn tý. Bộ dataset anh dùng ở trên là bộ dataset public của VIn BIgdata, còn VinAI là 1 P&L hoạt động độc lập khác của VIn.
Em mong anh có thể dành chút thời gian để chỉnh sửa lại bài viết để mọi người đỡ nhầm <3
Okie. Thanks em. Anh cũng hơi bị loạn về brandname của mấy cái đó 🙁
chào a, a có thể ra series về phát hiện ngã ko ạ
Vụ này anh chưa có data để làm 🙁
Dạ Anh ơi. em làm đến cái bước #Copy images và labels to train folder :
ngây chỗ dòng code : for file in total_files:
Nó báo lỗi là : TypeError: ‘int object is not iterable. Mong anh chỉ em ạ. em cám ơn ạ
Em post lên Group trao đổi, chia sẻ: https://facebook.com/groups/miaigroup nhé!
a Thắng ơi, learning rate của yolov5 nằm ở file nào thế ạ?
Em tìm file này nhé: yolov5/data/hyp.finetune.yaml
dạ e cám ơn a